Multimodal Personality Recognition using Cross-attention Transformer and Behaviour Encoding
Jul 1, 2022·,, ,·
0 min read
,·
0 min read
Tanay Agrawal
Dhruv Agarwal
Michal Balazia
Neelabh Sinha
Francois Bremond
 Architecture link
Architecture linkAbstract
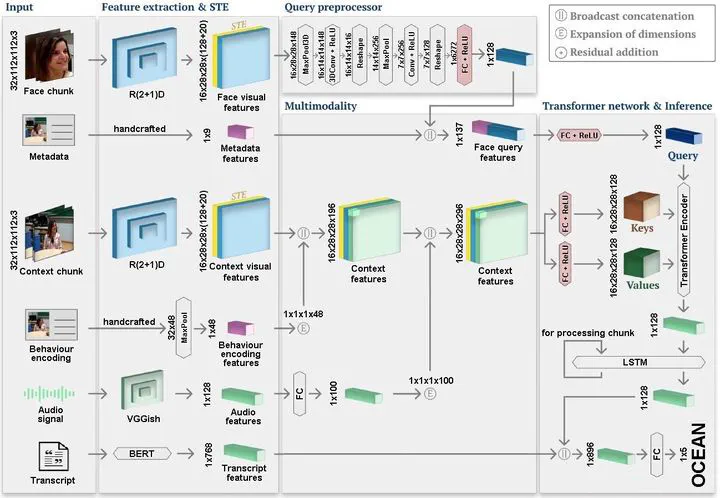
Personality computing and affective computing have gained recent interest in many research areas. The datasets for the task generally have multiple modalities like video, audio, language and bio-signals. In this paper, we propose a flexible model for the task which exploits all available data. The task involves complex relations and to avoid using a large model for video processing specifically, we propose the use of behaviour encoding which boosts performance with minimal change to the model. Cross-attention using transformers has become popular in recent times and is utilised for fusion of different modalities. Since long term relations may exist, breaking the input into chunks is not desirable, thus the proposed model processes the entire input together. Our experiments show the importance of each of the above contributions.
Type
Publication
17th International Conference on Computer Vision Theory and Applications (VISAPP), Virtual, February, 2022